Project Definition: WHAT’S THE REAL INFLUENCE OF ELON MUSK’ TWEEST OVER THE CRYPTO ECOSYSTEM?
Project Overview
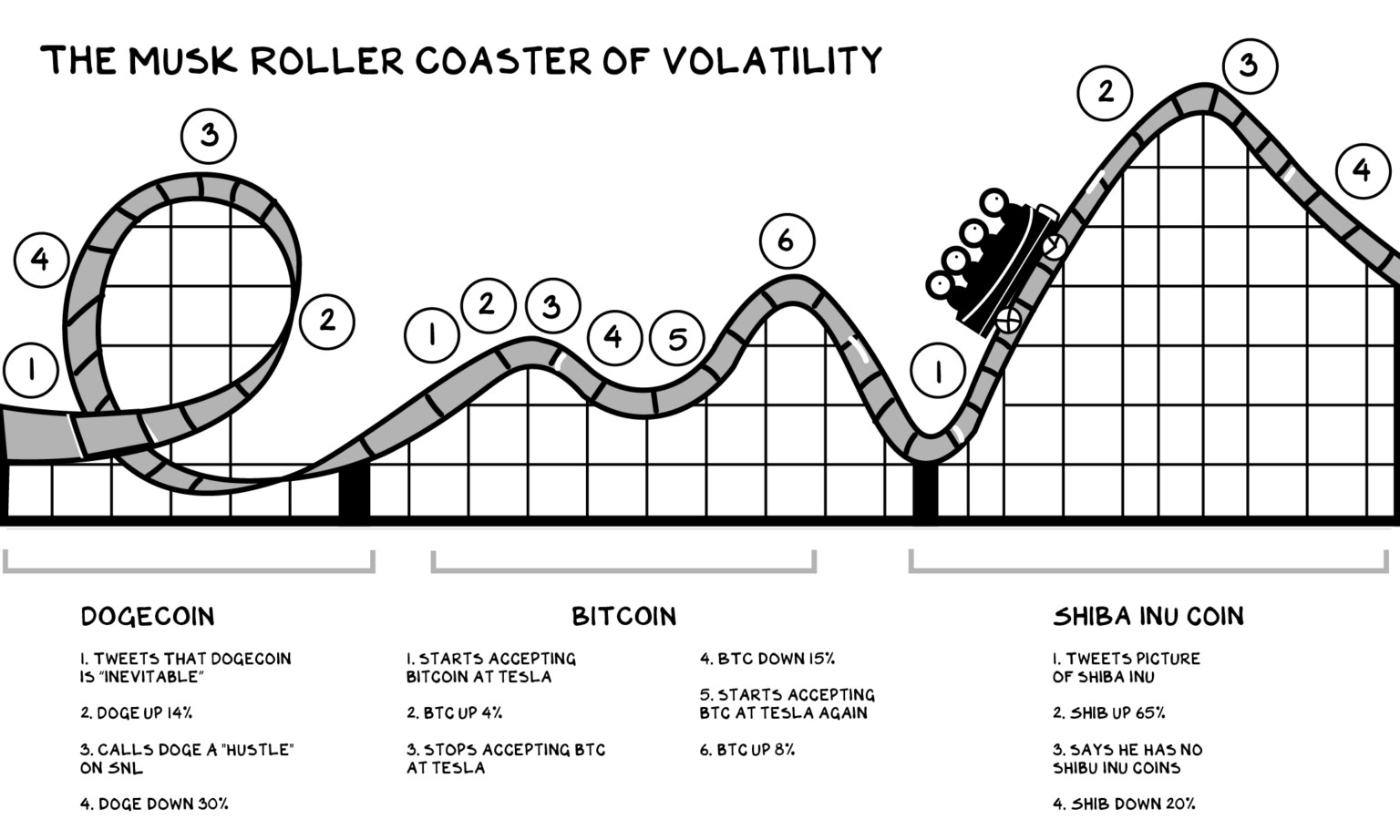
Lot has been said (here, here, and here,also here) about the influence of Elon Musk’ tweets over the cryptocurrency investors and ecosystem.

Their highly volatile price, relative lack of regulation compared to the stock market and newly-lowered barrier to entry make most cryptocurrencies an exciting and relatively easy investment for speculation (buying and hodling).[1]
Project Statement
This project expands the so called ‘Elon Effect’ and analyses the viability of predicting Bitcoin price fluctuations from the content of Elon Musk tweets. To achieve that, several supervised learning models are evaluated and optimized to find out if there is a direct relationship between the content of Elon Musk’s daily tweets and the price behavior of Bitcoin.
This project follows the CRISP-DM process model:
- Business Understanding: Building a highly predictive model to forecast Bitcoin behavior, based on Elon Musk daily tweets, presents an undisputable lucrative advantage.
- Data Collection: Crypto market data is collected using pandas data-reader library and yahoo finance API. Elon’s tweets are fetched using tweepy.
- Data Wrangling and Preparation: Preprocess tweets (removing stop words, hyperlinks, mentions,..) plus extract most popular (tweeted) words. Create new features considering if a tweet contains these words or not. Aggregate data by day.
- Data Modeling: Build and evaluate at least 3 different regression models. Determine which algorithm provides the lowest error and follows best pattern. Optimize it using GridCV.
- Results Evaluation: Evaluation of the predictor. Should we buy/sell?
Dive deeper into this project by checking this repo.
Metrics
MAE (mean absolute error) is very useful when the continuous target we want to predict follows a skewed distribution. Potential outliers/sparse data will not influence models attempting to optimize on this metric as much as, for instance, mean squared error.
A good model will allow us to predict near future bitcoin price. A model providing better results (lower error) would not be useful as it does not indicate what action to take in advance.
Analysis
Data Exploration:
The data used in this case study is publicly available in Twitter (collected via tweepy) and yahoo finance platforms (data-reader pandas library). Because this method only allows to fetch a few hundred of tweets per batch, this project also uses this dataset from Kaggle containing several years of Elon’s tweets is used. Selected training data is compressed between January-2019 and January-2022 (7278 tweets and replies) and test data from January-2022 to February-2022 (238 tweets). In machine learning, train/test data is usually randomly, as there’s no dependence from one observation to the other. However with time series data like this project target, we’ll test for a consecutive period after the one included training data.
Collected data from Twitter contains date/time and tweet’s text and also the number of likes, replies and retweets it received. For these 3 features the mean is much larger than the median (and than the 75 percentile), indicating a right skewed distribution.
A daily timeframe has been used in order to better isolate the effect of the Tweet on the crypto price, meaning that
Data Visualization:
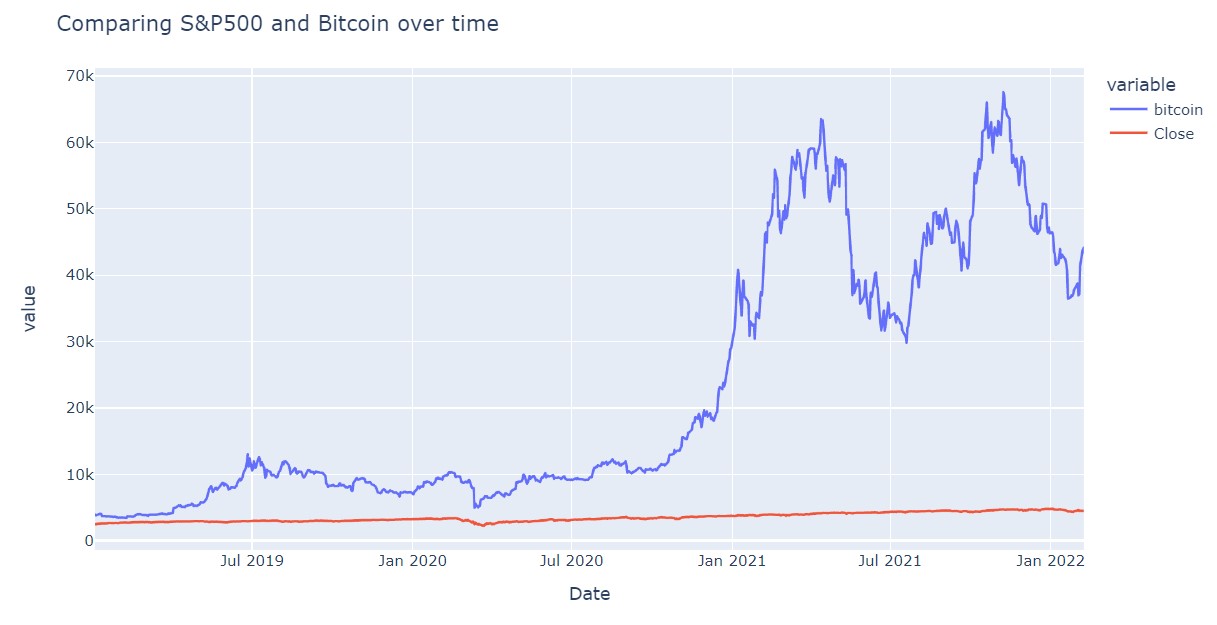
Comparing the value of Bitcoin and S&P500 from January2019 to February2022. Bitcoin is far more volatile than S&P500, but it’s growth is far faster.
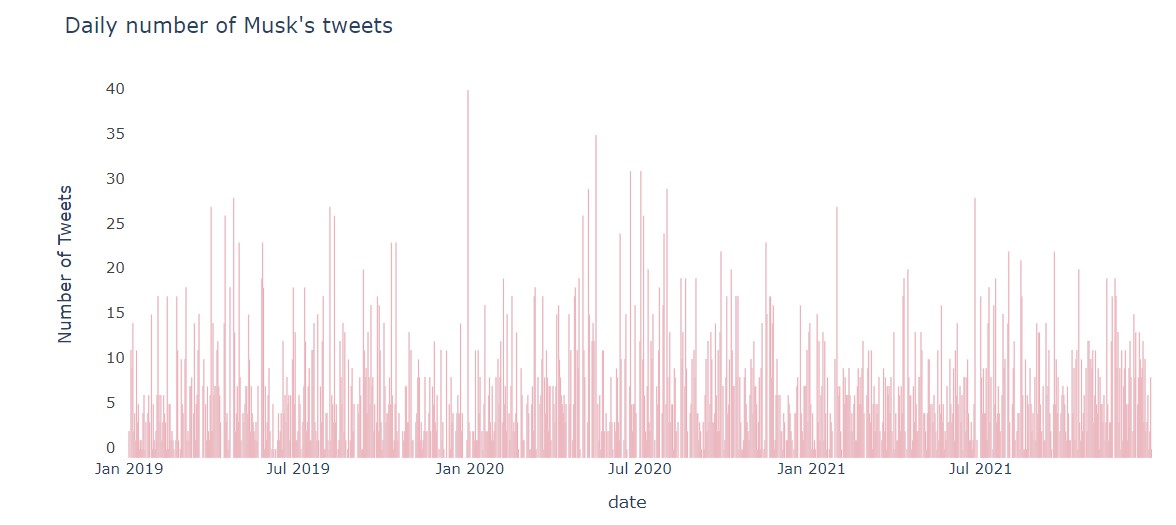
Elon not only leads two revolutionary companies, but he also is a prolific daily Twitter user.
METHODOLOGY:
Data Preprocessing:
The preprocessing of the text data is an essential step as it makes the raw text ready for mining, i.e., it becomes easier to extract information from the text and apply machine learning algorithms to less noisy data.Natural language processing (NLP) considering Twitter-specific syntax (such as hashtags, emoticons, and mentions) has been performed.
- Input: “Jenna went back to University”
- Normalize: “jenna went back to university”
- Tokenize: <”jenna”,”went”,”back”,”to”,”university”>
- Remove Stop Words: <”jenna”,”went”,”university>
- Stem/Lemmatize: <”jenna”,”go”,”univers”>
Bag of Words are useful vector space representations of words used in a Twitter context. By leveraging the huge amount of data available via the Twitter API (Elon most used word in training data, tweet datetime, number of retweets, comments and likes), this approach consists on encoding the subtext context of Tweets into the word embeddings without extensive manual labeling to harnessing for prediction. This is the main difference with much of the current available research studying the relationship between Twitter NLP and the stock market, which finds evidence of this relationship via sentiment classification [2].
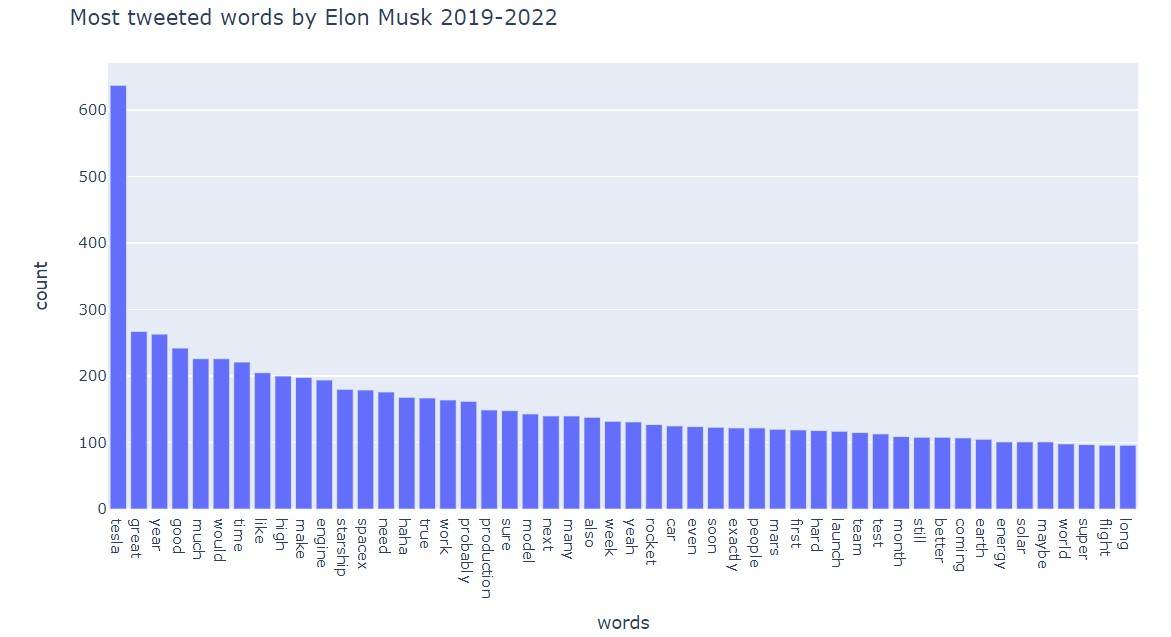
Other engineered features are the mention series (mention_crypto, mention_tesla and mention_spacex) that indicates 1/0 depending on if the text contains any of the words included in thematic lists. Tweet_len and clean_len that compares “info” volume got from text. Also, the date is decompose into day, month and year.
After aggregating the above features per day, the numerical features are normalized. Normalization ensures that each variable is treated equally when applying supervised learners (i.e. larger numbers does not have more weight than smaller ones).
The result is a spare matrix consolidated in a dataset.
Modeling & Implementation:
Three different regression models (Random Forest, Ada Boost and Gradient Boosting) have been evaluated to determine which algorithm will provide the lowest mean absolute error and the most convenient predictions trends. Gradient Boosting Regressor showed the second lowest MAE and its predictions follow a pattern very similar to real data, with the advantage of being offset.
Gradient Boosting Regressor was chose to be evaluated because of its strengths: High performance, robust with missing data and categorical features and fast training. Even though it is computationally expensive, hard to interpret and prone to overfit. Gradient Boosting algorithm uses an ensemble method called boosting. In boosting, decision trees are train sequencially in order to gradually improve the predictive power by using the previous tree error as a dependent variable.
Refinement
Gradient Boosting Regressor has been optimized using GridCV over the entire training set by tuning learning rate and number of estimators parameters to improve upon the untuned model’s MAE. The reason because I chose Gradient Boosting is because it not only presents the second best MAE on testing set but also, a similar behaviour with an interesting offset.
RESULTS
Model Evaluation and Validation
The following results are achieved after tuning the algorithm:
- Metric: MAE
- Unoptimized Model: 5693 ($)
- Optimized Model: 5469 ($)
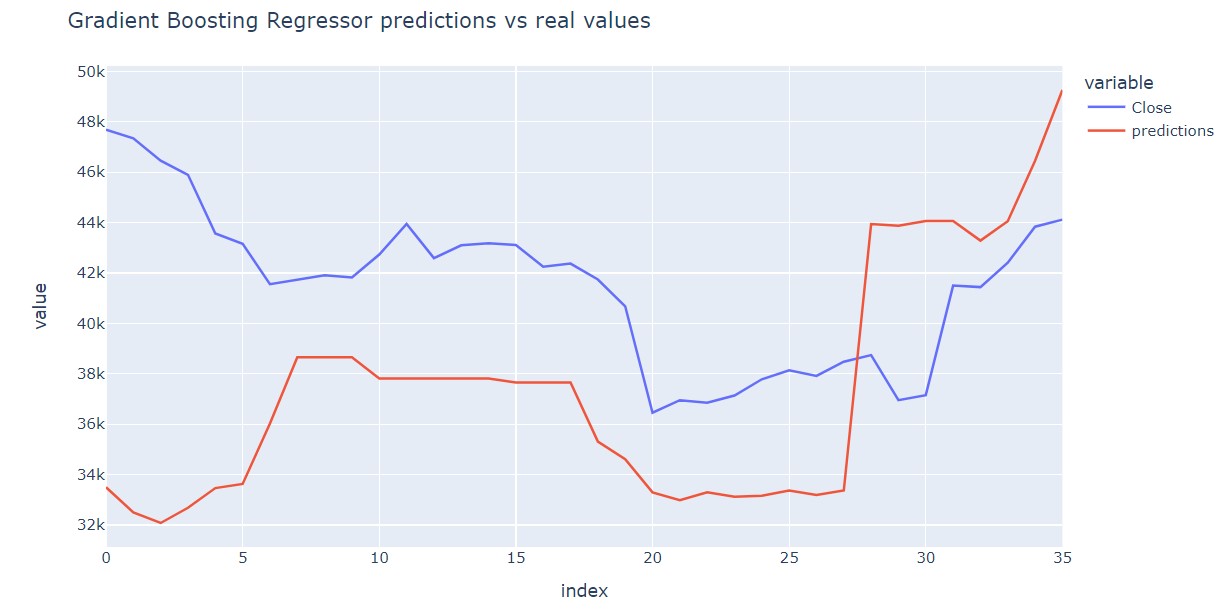
Interestingly, the model predictions trends and behaviour fit with real data with a preceeding offset that will allow a trader made buy/sell decisions in advance.
Justification
Predicting Bitcoin price within a 12% mean absolute error range and do it in advance its a wonderful result that exceeds my initial expectations.
CONCLUSION
Reflection & Improvement
My conclusion is that this study serves as a proof-of-concept identifying a clear link between the attributes and the target.
In order to significantly improve bitcoin price predictions to convert this project to a viable trading strategy, the following next steps are recommended:
- increasing bag of words or adding new sources (i.e Google Analytics searches for keywords).
- including tweets sentiment analysis as a new feature.
- time series decomposition and multi-output regression
Inspiration:
- [1] Mehta, Neel; Agashe, Adi; Detroja, Parth. Buble or Revolution
- [2] Michael Jermaann Predicting Stock Movement through Executive Tweets